Recurrent Neural Network
Motivation
在现实生活的许多场景中,我们都需要处理输入或输出为序列的数据,他们往往在时序关系上存在前后文之间的相互联系,输入与输出不一定相同所对相应的数据维数,如处理语言、音频文本、音乐生成等。
而对于传统的线性全连接层神经网络,由于输入数据时对于上下文的关系考虑较少,所以在处理序列问题上表现出的准确性较低,我们需要更多地考虑建立起能够充分考虑上下文文本关系的模型。
统计学工具
自回归模型
核心为基于给定时间段的输入情况有效估计将来参数
$$ P(x_{t}|x_{t-1},\dots,x_{t-\gamma}) $$
隐变量自回归模型
保留对过去观测的总结 h,并且同时更新下一步的观测值并总结 h
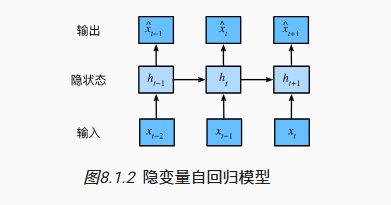
Notation
$$
\begin{align}
& x^{
数据预处理
文本预处理
对文本进行预处理是,首先我们读取数据集:
1
2
3
4
5
6
7
8
9
10
11
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine(): #@save
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
# 利用正则化表达删去非字母字符将其替换为空格,同时将字母均变为小写
lines = read_time_machine()
然后,我们将以行形式出现的文本拆分为一个个 Token(词元),Token 可以为一个词或者字符
1
2
3
4
5
6
def tokenize(lines, token='word'):
if token == 'word':
return [line.split() for line in lines]
if token == 'char':
return [list(line) for line in lines]
tokens = tokenize(lines)
将其初始输入的数据划分后,我们希望建立一个从输入的字符串到索引的词表 (Dictionary), 为达到这个目的,首先我们需要统计输入 Token 的词频并按词频排序,根据它们的词频分配唯一的数字索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
class Vocab: #@save
"""文本词表"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# 未知词元的索引为0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens): #@save
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
将每个 Token 表示为数字索引后,现在 Token 的数据形式依然不利于机器学习算法进行训练,我们考虑将其转换为 One-hot encoding 形式形成特征向量。
1
torch.nn.functional.one_hot(input_tensor, len(vocab))
读取长序列数据
由于文本序列是任意长的,我们希望将其划分为具有相同时间步数的子序列,每一个时间步 Token 的对应一个字符
随机采样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
顺序采样
1
2
3
4
5
6
7
8
9
10
11
12
13
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
循环神经网络
基本架构
我们先看最直观的输入序列长度等于输出序列长度的情况
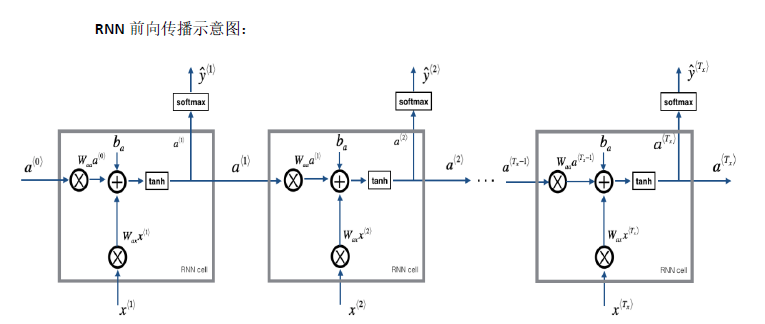
为了保持循环神经网络能够捕获序列前后问的特征,我们选择隐变量自回归模型,将前面多层累积的输入作为参数传递给下一层,同时下一层的循环模块也接受来自本层的输入
$$
\begin{align}
& a^{
一般对于生成隐藏层 $a^{
$$
a^{
[!Important] 参数共享
- 对于循环神经网络,由输入序列以及前一隐藏层对应的线性权重参数以及偏置均为共享参数
- 且由隐藏层到输出的参数也是共享参数
通过时间的反向传播 (Backpropagation through time)
我们先定义损失函数:
$$
\begin{align}
& L^{
8.7. 通过时间反向传播 — 动手学深度学习 2.0.0 documentation (d2l.ai)
由于对于循环神经网络,参数与输入的更新依赖于递归的公式进行,导致在反向传播的过程中梯度的计算非常复杂,且初始输入的微扰也可能给最终输出带来较大改变,因此我们考虑采取随机截断或在给定 time step 内截断的方法对梯度进行计算与更新。
不同类型的循环神经网络
我们之前所处理的循环神经网络是针对输入序列长度与输出序列长度一一对应的情况,但在实际需求中,我们所处理的经常是输入与输出不对等的情况,所以需要适当微调原有架构
梯度消失与爆炸
- 当循环神经网络层数加深后,我们会发现相对较前的权重很难通过网络架构将影响世家到后面,同时反向传播过程中针对误差所更新的参数也很难针对损失函数更新,这导致容易发生梯度消失
- 为了防止梯度不断增大发生爆炸,我们采用梯度裁剪的方式,每当梯度高于某个阈值就将其进行裁剪
梯度裁剪通常考虑将梯度 g 投影回给定半径的球来裁剪梯度,这样能够保持梯度范数永远不超过给定半径,同时保持原方向不变
$$ g = min\left( 1, \frac{\theta}{||g||} \right)g $$
优化单元
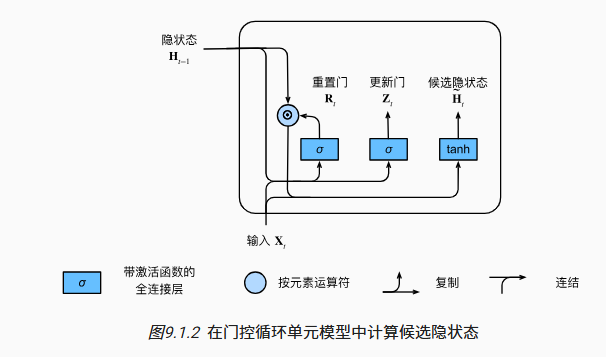
GRU: Gated Recurrent Unit
为了提升 RNN 的长期记忆能力,我们引入一个新的记忆单元 Memory Cell(候选的隐藏单元)与门阈值,来决定是否根据前后文语境情况更新
$$
\begin{align}
& \hat{c^{
GRU memory cell 的更新依赖于两方面:一者来自基于前一层的输入,另外一层则来自由较长上下文训练出来的结果,两者的权值通过 $\Gamma$ 作为 Gate 调节(通过 Sigmoid 函数更新至范围在 0 到 1 内)
计算候选的 $c^{
LSTM(long short term memory)
LSTM 相比 GRU 更加复杂,通过引入更新门 (the update gate) 与相关门 (the relevance gate) 以及输出门 (output gate) 来加强在长上下文中的记忆能力
$$
\begin{align}
& \hat{c^{
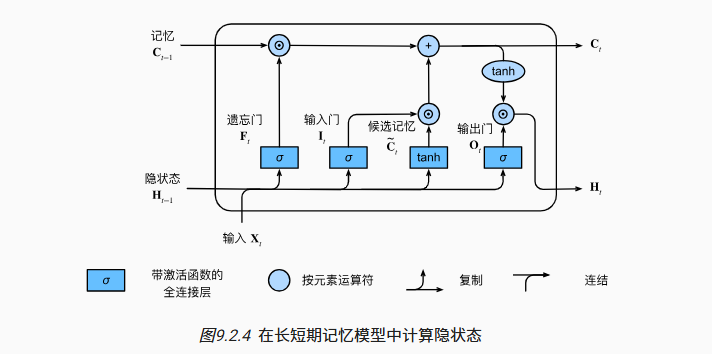
变体
双向循环神经网络 (Bidirectional RNN)
很多时候序列的输出不仅取决于序列输入的前文,也取决于序列输入的后文,这就需要我们改变神经网络的架构使得当下的输出考虑前后文的语境。
在双向循环神经网络中,我们不仅有前向的循环单元,还有反向的循环单元将序列最后的输入反向向前循环与反向传播不同
$$
\hat{y^{
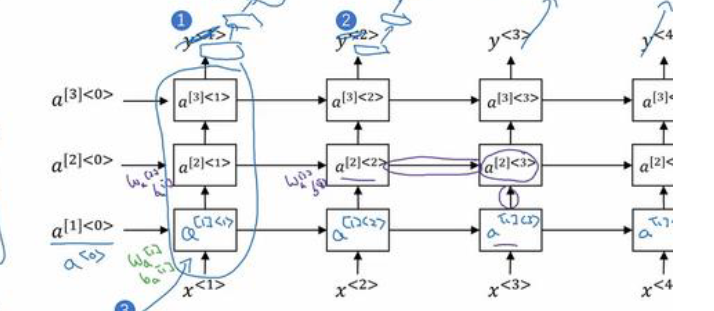
深层神经网络
在同一个时序步骤中并列加深神经网络层次,将低层的隐藏层输出作为高维的隐藏层输入
代码实现
1
2
3
4
5
6
7
8
9
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self)