Data Structure-4-BTree
#CS225
Motivation
为什么需要 B 树?
- 首先提出的问题很关键:我们总能把所有数据都放进主内存 (main memory) 吗? 答案是,特别对于现在的大型数据集来说,通常是不能 (No)。
- 那么,我们还能把数据存放在哪里呢?常见的答案是磁盘 (Disk) (比如硬盘驱动器 HDD 或固态硬盘 SSD),甚至是云存储 (Cloud Storage)。
- 这里的关键点在于,我们分析算法效率的标准方法——大 O 表示法 (Big-O notation),通常假设所有操作的时间是统一的 (uniform time)。这意味着它假设从内存访问数据大致花费相同的时间,不管数据在哪里。
问题:巨大的访问时间差异
- 事实上,当涉及到磁盘或云存储时,“统一时间”的假设是不现实的。
- CPU 速度: 一个 3GHz 的 CPU 可以在 1 毫秒 (ms) 内执行数百万 (3M) 次操作。这非常快。
-
磁盘速度 (旧观点): 传统上认为磁盘存储非常慢。
- 然而,现代存储如通过 M.2 插槽使用 PCIe 连接的 NVMe 固态硬盘 (NVMe SSDs) 对于顺序读写来说相当快 (例如,读取 3500 MB/s,写入 2500 MB/s)。
- 但是,大型传统机械硬盘 (HDDs) (例如 10TB+) 的吞吐量仍然慢得多 (例如,通过 SAS 接口约为 255 MB/s),更重要的是,它们有很高的寻道时间 (seek time) —— 即移动磁盘磁头到正确位置所需的时间。这个寻道时间主导了随机访问的性能。
- 云速度 (新观点): 通过网络访问云端数据会引入延迟 (latency),这可能相当可观 (例如,100 毫秒或更多)。
- 核心要点: 访问磁盘或云端数据的速度比访问主内存 (RAM) 或 CPU 缓存要慢几个数量级。可以这样想:访问 RAM 就像从你的桌子上拿一本书 (纳秒到微秒),访问 SSD 就像去本地图书馆分馆 (微秒到毫秒),而访问机械硬盘或云端则像是从国家图书馆档案库订购一本书 (毫秒到数百毫秒)。
为什么标准树 (如 AVL 树) 在磁盘上表现不佳
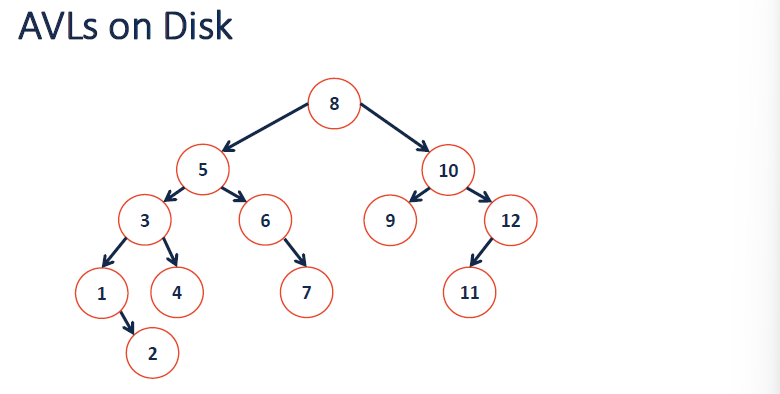
- 我们考虑使用一个平衡二叉搜索树,比如 AVL 树 (AVL Tree),但是将它的节点存储在磁盘上。
-
示例: 在示例 AVL 树中查找
6.5。沿着树向下走的每一步 (例如,根节点 8 -> 5 -> 6 -> 7) 都需要从磁盘读取一个节点。 - 如果每次磁盘访问需要
100ms(对于某些场景是现实的延迟),并且这条路径的树高为 4,那么这次搜索需要4 * 100ms = 400ms。这还是对于一个只有 12 个节点的微型树! -
实际应用: 想象一下存储中国所有人的驾驶记录。
- 记录数量:我们估计有 5 亿 (
500m) 条。 - 数据总量:如果每条记录是 5MB,总大小是
5MB * 500m = 2500m MB = 2.5k TB = 2.5 PB(Petabytes,拍字节)。这显然无法放入内存。 - AVL 树深度:一个平衡二叉树的高度
h大约是 $h \approx \log_2 n$。对于 $n = 500 \times 10^6$,$h \approx \log_2(5 \times 10^8) \approx 29$。所以,假设高度约为30。 - 搜索时间:如果每次磁盘访问耗时
100ms,一次搜索可能需要高达 $h \times 100ms \approx 30 \times 100ms = 3000ms = 3$ 秒!对于许多应用来说,这太慢了。
- 记录数量:我们估计有 5 亿 (
- 结论: 二叉搜索树,即使是像 AVL 这样的平衡树,对于基于磁盘的存储来说也太高了,因为树的高度直接转化为慢速磁盘访问的次数。
BTree Basic
Motivation
- 认识到磁盘/网络访问 (寻道时间或延迟) 是瓶颈后,我们想要一种树结构能够:
- 保持树的高度尽可能矮 (Keep trees short)。
- 确保每次读取的数据是相关的 (Make sure data is relevant),并且最大化每次读取获得的信息量。这意味着一次读取更多的数据 (一个更大的节点)。
B 树节点结构
-
阶 (order) 为
m的 B 树 (B-Tree) 正是为了这个目的而设计的。 -
节点内容: B 树中的每个节点包含多个键 (以及关联的值/指针),并以有序的方式存储。幻灯片展示了一个节点
[-3, 8, 23, 25, 31, 42, 43, 55]。这看起来像是节点内部的一个排序数组 (Sorted array)。这里提到了m=9,这似乎与这个节点如果是内部节点时 可能 拥有的指针数量有关 (我们稍后会澄清属性)。节点本身通常被称为BTreeNode。 - 目标: 最小化读取次数!
-
节点大小: 我们构建树时,使每个节点的大小大致对应于 I/O 的自然块大小。例如,一个节点可能被设计成适合:
- 一个磁盘块 (disk block) (例如 4KB, 8KB)
- 一个网络包 (network packet)
- 幻灯片给出了一个例子:每个节点
1500B。
- 技术比喻 (Technical Analogy): 可以把 B 树节点想象成一本非常厚的书的章节索引。它不像二叉树那样每个索引条目指向单个页面,而是列出了在一个页面范围内的多个主题 (键),并指向该范围的开始 (子节点指针)。通过查看章节索引 (一次读取),你比只查看单个条目能更显著地缩小搜索范围。
BTree Operations
Insertion
-
定义: 阶 (order) 为
m的 B 树是一个m路树 (m-way tree),意味着节点最多可以有m个子节点。- 节点内的键是有序的 (ordered)。
- 节点最多包含
m-1个键。 (这意味着最多有m个子节点指针)。
-
插入过程:
- 找到新键所属的合适的叶子节点 (类似于 BST 搜索)。
- 将键插入叶子节点,并保持有序。
-
处理节点溢出 (分裂 Split):
- 如果插入一个键导致节点包含
m个键 (即节点溢出),我们必须分裂 (split) 该节点。 -
示例 (
m=5): 一个节点初始有键[3, 9, 17, 21]。我们插入16。节点变为[3, 9, 16, 17, 21]。它现在有m=5个键,太多了。-
分裂节点: 找到中间键 (median key)。对于
[3, 9, 16, 17, 21],中间键是16。 -
提升中间键: 将中间键 (
16) “扔到 (Throw up)” 父节点 (parent node)。 -
创建新节点: 小于中间键的键 (
[3, 9]) 组成一个新的左节点。大于中间键的键 ([17, 21]) 组成一个新的右节点。 - 这两个新节点成为父节点的子节点,通过被提升的键 (
16) 连接。
-
分裂节点: 找到中间键 (median key)。对于
- 如果插入一个键导致节点包含
- 递归分裂: 如果提升一个键导致父节点也溢出,则分裂过程会递归地向上传递。如果根节点 (root) 分裂,会创建一个新的根节点,它只包含从旧根节点分裂出的中间键,树的高度增加一。
-
幻灯片示例:
- 幻灯片展示了一个例子,从将
16插入[3, 9, 17, 21](m=5) 开始。节点变为[3, 9, 16, 17, 21]。中间键16被提升。左子节点[3, 9],右子节点[17, 21]。 - 然后,键
35, 80, 225被插入到右子节点[17, 21]中。它变成[17, 21, 35, 80, 225]。中间键35被提升到根节点。左子节点[17, 21],右子节点[80, 225]。根节点现在包含[16, 35]。 - (注意: 幻灯片 33-35 展示的似乎是一个略有不同/简化的分裂示例,其中
80从[21, 35, 80, 225]中被提升,导致根节点为[17, 80],子节点为[3, 9],[21, 35],[225, 216??]。我们还是遵循前面和幻灯片 30-32 展示的标准中值提升方法。)
- 幻灯片展示了一个例子,从将
可视化Btree Operation B-Tree Visualization
BTree Properties
让我们总结一下阶为 m 的 B 树的正式属性:
- M 路树 (M-Way Tree): 它是一个 m 路搜索树。
- 节点内键的数量: 除根节点外,每个节点包含 $k$ 个键,其中 $\lceil m/2 \rceil - 1 \le k \le m-1$。节点内的键是有序的。
- 内部节点的子节点数量: 一个包含 $k$ 个键的内部节点恰好有 $k+1$ 个子节点。
-
根节点 (Root Node):
- 如果根节点是叶子节点 (树只有一个节点),它可以包含 0 到 $m-1$ 个键。
- 如果根节点是内部节点,它有 2 到 $m$ 个子节点。(这意味着它包含 1 到 $m-1$ 个键)。
- 内部节点 (非根) 的子节点数量: 所有非根内部节点必须有 $c$ 个子节点,其中 $\lceil m/2 \rceil \le c \le m$。
- 叶子节点层级: 所有叶子节点都在同一层 (same level) (即具有相同的深度)。这确保了树在高度上是平衡的。
Search
- 搜索过程类似于二叉搜索树,但更为通用。
-
算法:
- 从根节点开始。
- 在当前节点内,查找键
K,或者确定K应该在哪个区间 $(key_i, key_{i+1})$。(这可以通过在节点内部的有序键上进行线性扫描或二分查找来完成)。 - 如果在节点中找到了
K,返回成功/关联的值。 - 如果在节点中未找到
K并且该节点是叶子节点,则K不在树中。返回失败。 - 如果在节点中未找到
K并且该节点是内部节点,则沿着对应于步骤 2 中确定的区间的子节点指针向下查找 (如果是 $K < key_i$,则为指针i;如果是 $key_i < K < key_{i+1}$,则为指针i+1,依此类推)。 -
关键之处: 跟随子节点指针通常需要从磁盘/网络读取子节点。这就是
node._fetchChild(i)操作,并且是缓慢的步骤 (例如,100ms)。 - 使用获取到的子节点,从步骤 2 开始重复。
-
示例 (幻灯片 52-53): 在
m=3的树中查找43。- 根节点
[23]。43 > 23。跟随右子指针。获取节点[42, 55](成本:1 次磁盘读取,例如 100ms)。 - 节点
[42, 55]。43在42和55之间。跟随中间子指针。获取节点[43](成本:1 次磁盘读取,例如 100ms)。 - 节点
[43]。找到43。总成本:2 次磁盘读取。
- 根节点
Code Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
#include <vector>
#include <iostream>
#include <algorithm>
#include <memory> // For std::unique_ptr, std::make_unique
// 假设 Key 类型是 int
using Key = int;
// 前向声明 BTree 类,以便 BTreeNode 可以引用它
template <int M> // M 是 B 树的阶 (Order)
class BTree;
// B 树节点结构体
template <int M> // M is the order of the B-Tree
struct BTreeNode {
bool isLeaf = true;
std::vector<Key> keys; // 节点中的键
std::vector<std::unique_ptr<BTreeNode<M>>> children; // 指向子节点的指针向量
// 对于内部节点,数量 = keys.size() + 1
// 对于叶节点,此向量通常为空或未使用
// (为了简化,省略构造函数、析构函数等)
// --- 搜索辅助函数 ---
// 在节点内查找键或应该插入的位置 (返回索引 i)
//使得 keys[i] >= key 或者 i == keys.size()
int find_location(const Key& key) const {
// 简单的线性扫描 (对于大的 M,二分查找更优)
int i = 0;
while (i < keys.size() && key > keys[i]) {
i++;
}
return i;
}
// --- 插入辅助函数 ---
// 在叶节点中插入键 (不处理溢出)
void insert_key_leaf(const Key& key) {
int i = find_location(key);
keys.insert(keys.begin() + i, key);
}
// 在内部节点中插入键和子节点指针 (不处理溢出)
void insert_key_internal(const Key& key, std::unique_ptr<BTreeNode<M>> left_child, std::unique_ptr<BTreeNode<M>> right_child) {
int i = find_location(key);
keys.insert(keys.begin() + i, key);
// 在 i+1 处插入新的右子节点,原来的 children[i] 成为新左子节点
children.erase(children.begin() + i); // 移除原来的指针
children.insert(children.begin() + i, std::move(left_child)); // 插入左子节点
children.insert(children.begin() + i + 1, std::move(right_child)); // 插入右子节点
}
};
// --- 分裂结果结构体 ---
// 用于在递归插入中向上传递分裂信息
template<int M>
struct SplitResult {
bool split_occurred = false;
Key promoted_key; // 提升到父节点的键
std::unique_ptr<BTreeNode<M>> new_sibling; // 分裂产生的新右兄弟节点
};
// B 树类
template <int M> // M 是 B 树的阶 (Order)
class BTree {
static_assert(M >= 3, "B-Tree order M must be at least 3");
private:
std::unique_ptr<BTreeNode<M>> root_ = nullptr;
const int minKeys_ = (M + 1) / 2 - 1; // 最小键数 (ceil(M/2) - 1)
const int maxKeys_ = M - 1; // 最大键数
// --- 搜索的私有递归辅助函数 ---
bool _search(const BTreeNode<M>* node, const Key& key) const {
if (!node) {
return false; // 空树或未找到
}
int i = node->find_location(key);
// 检查是否在当前节点找到
if (i < node->keys.size() && node->keys[i] == key) {
return true;
}
// 如果是叶节点且未找到,则键不存在
if (node->isLeaf) {
return false;
}
// --- 模拟磁盘读取 ---
// 在实际应用中,这里需要从磁盘加载 node->children[i]
// std::unique_ptr<BTreeNode<M>> child_node = fetchChild(node->children_raw_pointers[i]);
// 向下递归到正确的子节点
return _search(node->children[i].get(), key);
}
// --- 插入的私有递归辅助函数 ---
SplitResult<M> _insert(BTreeNode<M>* node, const Key& key) {
SplitResult<M> result; // 默认 split_occurred = false
if (node->isLeaf) {
// 1. 如果是叶节点,直接插入
node->insert_key_leaf(key);
// 2. 检查是否溢出
if (node->keys.size() > maxKeys_) {
// 需要分裂
result = split_node(node);
}
// 返回结果 (可能分裂,也可能没分裂)
return result;
} else {
// 3. 如果是内部节点,找到应该插入的子树
int i = node->find_location(key);
// --- 模拟磁盘读取子节点 ---
// BTreeNode<M>* child_node = fetchChild(node->children_raw_pointers[i]);
// 4. 递归插入到子节点
SplitResult<M> child_split_result = _insert(node->children[i].get(), key);
// 5. 检查子节点是否发生了分裂
if (child_split_result.split_occurred) {
// 子节点分裂了,需要将提升的键和新兄弟节点插入当前节点
node->insert_key_internal(child_split_result.promoted_key,
std::move(node->children[i]), // 旧的子节点成为新左子节点
std::move(child_split_result.new_sibling));
// 6. 检查当前节点是否因为插入提升的键而溢出
if (node->keys.size() > maxKeys_) {
// 当前节点也需要分裂
result = split_node(node);
}
}
// 返回结果 (可能因为子节点分裂导致当前节点分裂,也可能没有)
return result;
}
}
// --- 分裂节点的辅助函数 ---
SplitResult<M> split_node(BTreeNode<M>* node) {
SplitResult<M> result;
result.split_occurred = true;
// 找到中间位置
int median_idx = node->keys.size() / 2;
result.promoted_key = node->keys[median_idx]; // 提升中间键
// 创建新的右兄弟节点
result.new_sibling = std::make_unique<BTreeNode<M>>();
result.new_sibling->isLeaf = node->isLeaf;
// 将中间键之后的键移动到新兄弟节点
result.new_sibling->keys.assign(node->keys.begin() + median_idx + 1, node->keys.end());
// 如果不是叶节点,还需要移动相应的子节点
if (!node->isLeaf) {
int children_median_idx = (node->children.size() + 1) / 2; // 子节点分裂点
result.new_sibling->children.assign(
std::make_move_iterator(node->children.begin() + children_median_idx),
std::make_move_iterator(node->children.end())
);
node->children.resize(children_median_idx); // 从原节点移除移动的子节点
}
// 从原节点移除中间键及移动的键
node->keys.resize(median_idx);
return result;
}
public:
// --- 公共搜索接口 ---
bool search(const Key& key) const {
return _search(root_.get(), key);
}
// --- 公共插入接口 ---
void insert(const Key& key) {
// 1. 如果树为空,创建根节点
if (!root_) {
root_ = std::make_unique<BTreeNode<M>>();
root_->isLeaf = true;
root_->keys.push_back(key);
return;
}
// 2. 从根节点开始递归插入
SplitResult<M> root_split_result = _insert(root_.get(), key);
// 3. 处理根节点分裂的特殊情况
if (root_split_result.split_occurred) {
// 创建新的根节点
auto new_root = std::make_unique<BTreeNode<M>>();
new_root->isLeaf = false;
new_root->keys.push_back(root_split_result.promoted_key);
new_root->children.push_back(std::move(root_)); // 旧根成为左子节点
new_root->children.push_back(std::move(root_split_result.new_sibling)); // 新兄弟成为右子节点
root_ = std::move(new_root); // 更新树的根
}
}
// (可以添加打印树结构、删除等其他方法)
};
代码说明:
-
BTreeNode结构体:-
isLeaf: 标记是否为叶节点。 -
keys: 存储节点中的键,使用std::vector。 -
children: 存储指向子节点的std::unique_ptr。使用智能指针可以简化内存管理。对于内部节点,其大小比keys多一个。 -
find_location: 辅助函数,用于在节点内查找键或确定其应插入的位置。 -
insert_key_leaf/insert_key_internal: 简化版的插入,仅将键(和子节点)放入向量,不处理溢出。
-
-
SplitResult结构体:- 用于在递归插入时,从子节点向父节点传递分裂信息,包括是否发生分裂、被提升的键以及新创建的右兄弟节点。
-
BTree类:-
M: 模板参数,表示 B 树的阶。 -
root_: 指向根节点的智能指针。 -
minKeys_,maxKeys_: 根据阶M计算的节点最小和最大键数。 -
_search(私有): 递归搜索辅助函数。- 首先在当前节点内查找。
- 如果找到或当前是叶节点,则返回。
- 否则,递归进入相应的子节点 (
node->children[i].get())。注释中标明了实际应用中需要模拟磁盘读取的位置。
-
_insert(私有): 递归插入辅助函数。-
叶节点: 直接插入,如果溢出则调用
split_node,并返回分裂结果。 -
内部节点: 找到正确的子节点递归插入。如果子节点返回了分裂结果,则将提升的键和新兄弟插入当前节点。如果当前节点也因此溢出,则调用
split_node并返回分裂结果。
-
叶节点: 直接插入,如果溢出则调用
-
split_node(私有): 执行节点分裂的逻辑。- 找到中间键。
- 创建新兄弟节点。
- 将原节点中大于等于中间索引的键和相应的子节点(如果是内部节点)移动到新兄弟节点。
- 调整原节点的键和子节点数量。
- 返回包含提升键和新兄弟节点的
SplitResult。
-
search(公共): 公开的搜索接口,调用私有辅助函数。 -
insert(公共): 公开的插入接口。- 处理空树的特殊情况。
- 调用私有辅助函数
_insert。 -
处理根节点分裂: 如果
_insert返回表明根节点发生了分裂,需要创建一个新的根节点,将旧根和新兄弟作为其子节点。
-
关键点回顾:
- 递归: 搜索和插入都是通过递归实现的。
- 分裂: 插入操作的核心是节点分裂机制,它保证了树的平衡和 B 树属性的维护。
-
磁盘 I/O (模拟): 代码中用注释标出了实际需要进行磁盘读取(
fetchChild)或写入(节点更新/分裂)的位置。这是 B 树性能的关键所在。 -
阶 M:
M的选择影响节点的容量和树的高度,进而影响性能。
BTree Analysis
BTree 属性回顾
-
m 路搜索树 (m-way tree): 每个节点最多有
m个子节点。 - 有序性: 节点内的所有键都是排序的。
-
键数量限制:
- 所有节点最多包含
m-1个键。 - (更精确地说,除了根节点) 非根节点至少包含 $\lceil m/2 \rceil - 1$ 个键。
- 所有节点最多包含
-
子节点数量限制:
- 一个包含
k个键的内部节点恰好有k+1个子节点。 - 根节点 (如果不是叶子) 至少有 2 个子节点,最多有
m个子节点。 - 所有非根内部节点至少有 $\lceil m/2 \rceil$ 个子节点,最多有
m个子节点。
- 一个包含
- 平衡性: 所有叶子节点都在同一层级 (same level)。这是 B 树能够保证高效搜索的关键。
Height Analysis
这部分是 B 树理论的核心,解释了为什么 B 树如此高效。
分析目标与策略
-
目标: 找到 B 树的总键数
n(number of keys) 和树高h(height) 之间的关系。 -
动机: 树的高度
h决定了在搜索、插入或删除操作中,最多需要进行的磁盘读取/寻道次数 (fetches / reads / seeks) (幻灯片 15)。因为磁盘访问非常耗时,我们希望h尽可能小。 - 核心思想: (幻灯片 19-21) 证明 B 树的高度是对数级别的,即 $h = O(\log_m n)$ (幻灯片 17-18)。
-
策略: (幻灯片 22) 采用与 AVL 树分析类似的方法:通过确定给定高度
h的 B 树最少能包含多少节点/键,来反向推导出给定键数n时树的最大可能高度h。即找到关于n和h的不等式。
推导最小节点数和最小键数
为了找到高度 h 的 B 树包含的最小键数 n_min,我们首先计算最稀疏 (节点数最少) 的 B 树结构。
- 定义最小分支度: 让 $t = \lceil m/2 \rceil$。这是非根内部节点允许的最小子节点数 (幻灯片 27)。
-
各层最小节点数:
- Level 0 (Root): 至少 1 个节点。
- Level 1: 根节点至少有 2 个子节点。所以 Level 1 至少 2 个节点 (幻灯片 26)。
- Level 2: Level 1 的每个节点 (至少 2 个) 都是非根节点,它们各自至少有
t个子节点。所以 Level 2 至少 $2 \times t$ 个节点 (幻灯片 29)。 - Level 3: Level 2 的每个节点 (至少 $2t$ 个) 至少有
t个子节点。所以 Level 3 至少 $2t \times t = 2t^2$ 个节点 (幻灯片 31)。 - …
- Level h (假设是叶子层): 至少有 $2t^{h-1}$ 个节点 (幻灯片 32)。
-
最小总节点数 (推导过程,幻灯片 33-38): 将各层最小节点数相加得到总的最小节点数 $N_{min}$。 $$ N_{min} \ge 1 (\text{root}) + 2 (\text{lvl 1}) + 2t (\text{lvl 2}) + … + 2t^{h-1} (\text{lvl h}) $$ 这是一个几何级数求和 (除了第一项)。 $$ N_{min} \ge 1 + 2 (1 + t + t^2 + … + t^{h-1}) = 1 + 2 \frac{t^h - 1}{t-1} $$
-
最小总键数
n_min:- 根节点至少有 1 个键。
- 其他所有节点 (非根节点) 至少有 $t-1 = \lceil m/2 \rceil - 1$ 个键。
- 将最小节点数乘以每个节点的最小键数 (并考虑根节点的特殊性) 可以得到总的最小键数
n。 - 一个更简洁且常用的结果是,对于高度为
h(h>=1) 的 B 树,总键数n满足: $$ n \ge 2t^h - 1 \quad (\text{其中 } t = \lceil m/2 \rceil) $$ 这个公式 $n_{min} = 2t^h - 1$ 给出了高度为h的 B 树能够容纳的最少键数。
推导高度的上界
我们从上面得到的关于最小键数的不等式出发,来求解 h 的上界:
- 我们有不等式: $n \ge 2t^h - 1$ (幻灯片 55)
- 整理得到: $n + 1 \ge 2t^h$
- 进一步整理: $\frac{n+1}{2} \ge t^h$
- 两边取以
t为底的对数 ($\log_t$) : $\log_t \left( \frac{n+1}{2} \right) \ge \log_t(t^h)$ - 得到: $\log_t \left( \frac{n+1}{2} \right) \ge h$
-
即高度
h的上界为: $$ h \le \log_t \left( \frac{n+1}{2} \right) = \log_{\lceil m/2 \rceil} \left( \frac{n+1}{2} \right) $$ -
结论: 这个结果表明,B 树的高度
h是以 $\lceil m/2 \rceil$ (约等于 $m/2$) 为底,关于键数n的对数关系。因此,记作 $h = O(\log_m n)$。由于m通常远大于 2 (例如 100, 1000),这个对数的底数很大,使得h的增长非常缓慢,即使n非常大,h也通常很小。
示例计算
- 给定: $m=101$, $h=4$ (幻灯片 47)。
- 计算 $t = \lceil m/2 \rceil = \lceil 101/2 \rceil = 51$ (幻灯片 50)。
- 最小键数: $n_{min} = 2t^h - 1 = 2 \times (51)^4 - 1 = 2 \times 6,765,201 - 1 = 13,530,401 \approx 13.5$ 百万。 这意味着一个阶为 101、高度仅为 4 的 B 树,至少能存储超过 1350 万个键!
- 最大键数: 每个节点最多 $m-1 = 100$ 个键。总节点数最多大约 $m^h$ 级别。最大键数 $n_{max}$ 会非常大 (远超最小键数)。一个粗略的上界 $n_{max} < m^{h+1} = 101^5 \approx 10^{10}$ (百亿级别)。
- 性能影响: (幻灯片 52) 即使有千万甚至上亿的键,树的高度也可能只有 3 或 4。如果每次磁盘读取耗时 75ms,查找最多只需要 $4 \times 75ms = 300ms$,这是非常高效的。
- 反向计算: (幻灯片 59) 如果 $n=1$ 百万 ($1M$), $m=101$ ($t=51$),那么最大高度 $h \le \log_{51}(\frac{1M+1}{2}) \approx \log_{51}(500,000) \approx \frac{\log_{10}(500k)}{\log_{10}(51)} \approx \frac{5.7}{1.7} \approx 3.35$。所以高度最多为 3。